Bonjour !
La dernière fois nous avons traité le cas des fichiers encodés en utf-8 mais qu'en est-il des fichiers qui sont encodés différemment ?
Pour répondre à cette question, nous allons d'abord utiliser iconv. Pour que cette solution fonctionne, il faut que la valeur de l'encodage de la page aspirée soit compatible avec les encodages connus d'iconv. Si la valeur est connue d'iconv, on fera un dump puis la conversion (transformer en utf-8).
En revanche, si la valeur n'est pas connue, on aura un nouveau problème que l'on essaiera de résoudre en allant chercher le charset.
Il existe 2 options très utiles pour la commande iconv : -f et -t qui spécifient respectivement l'encodage de départ et l'encodage d'arrivée. Il est nécessaire de rediriger le résultat de la commande dans un fichier car iconv affiche à l'écran par défaut.
Que faire si la valeur d'encodage n'est pas connue d'iconv ?
Si la valeur n'est pas connue d'iconv, nous devons extraire le charset des pages aspirées. Pour cela, nous avons la commande egrep qui est une commande de filtrage de lignes dans un fichier. Son intérêt est de pouvoir travailler avec des expressions régulières.
Syntaxe : egrep motif fichier
egrep prend 2 arguments : un motif de recherche et un fichier dans lequel on effectue cette recherche. Le motif peut s'exprimer sous la forme d'une expression régulière. Attention à la casse, si le motif recherché par egrep est connu d'iconv, cette valeur est affichée à l'écran.
Quelques options d'egrep :
- -c : compte le nombre de lignes qui contiennent le motif recherché
- -v : affiche les lignes qui ne contiennent pas le motif
- -vc : compte le nombre de lignes du fichier qui ne contiennent pas le motif
- -n : affiche les lignes, précédées de leur numéro
- -i : on cherche le motif en ne tenant pas compte de la casse
- -o : affiche les chaînes de caractères reconnues par le motif
- -uniq : filtre les doublons mais en les comptant
Voici donc où nous en sommes dans le programme et dans le tableau HTML (cliquez sur les images pour les agrandir) :
 |
| Programme partie 1 |
 |
| Programme partie 2 |
 |
| Programme partie 3 |
 |
| Programme partie 4 |
 |
| Programme partie 5 |
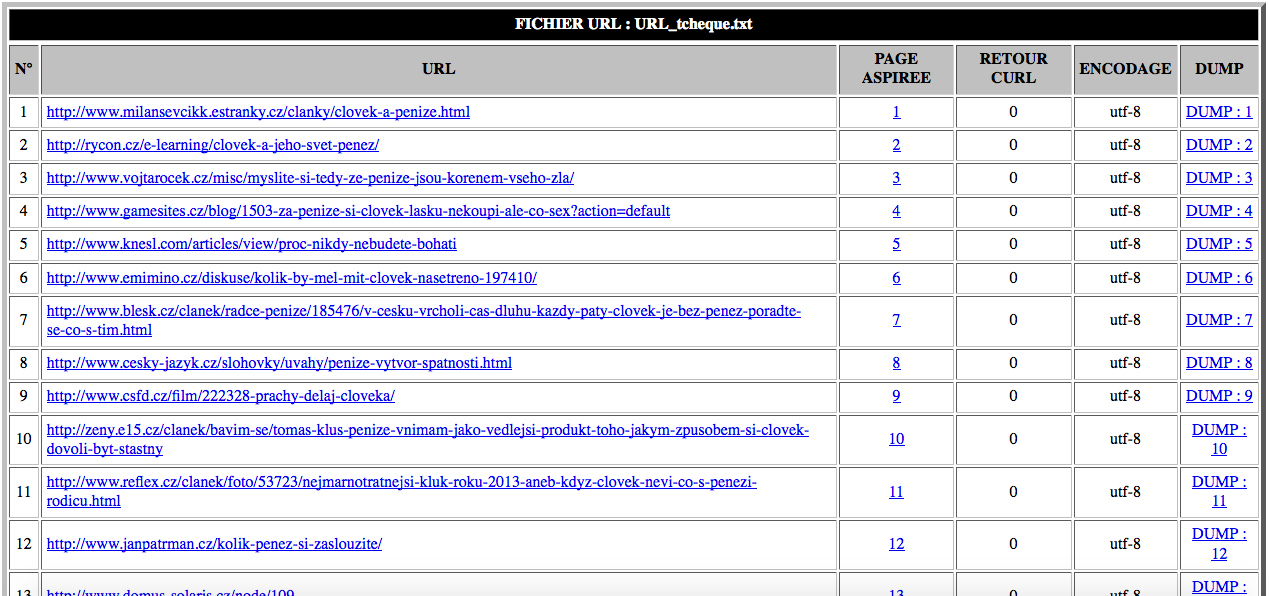 |
| Tableau HTML Tchèque |
 |
| Tableau HTML Anglais |
.png) |
| Tableau HTML Espagnol (erreur) |
 |
| Tableau HTML Espagnol |
 |
| Tableau HTML Français |
Dans les captures d'écran, vous pouvez voir que nous rencontrons essentiellement deux types d'erreurs : soit l'accès à une page est interdite (403 Forbidden), soit la page a été déplacée (307 Moved Permanently). Mais ce que l'on ne voit pas ici, c'est que nous avons aussi quelques soucis avec l'expression régulière utilisée dans notre programme pour extraire le charset car elle ne fonctionne pas sur toutes les pages aspirées (sans doute n'est-elle pas assez générale ?). Il nous faut également revoir l'aspiration de certaines pages car elle ne s'est pas toujours effectuée correctement (souci avec la commande curl). Nous allons essayer de faire quelques petits réglages dans les semaines qui viennent.
A bientôt pour la suite !
Pour la regexp permettant d'extraire le charset, essayer ceci :
RépondreSupprimercharset=(\"|\')?[^\"\']+(\"|\')?
en gros, le contenu du charset : [^\"\']+
est entouré de (\"|\')? et (\"|\')?
i.e de ce type "utf-8" ou 'utf-8' ou utf-8 etc.(un mélange des 2)
SF